Progress report: Profiling Celeritas on Nvidia GPUs
The University of Sheffield
2024-01-23
GPUs
- Development machine:
- NVIDIA Titan V (SM 70, 250W)
- Intel i7-6850K
- TUoS Stanage HPC (Tier 3):
- NVIDIA H100 PCI-e (SM 90, 350W)
- NVIDIA A100 SXM4 (SM 80, 500W)
- AMD EPYC 7413
- Exclusive reservation to use
ncu

Timeline without NVTX
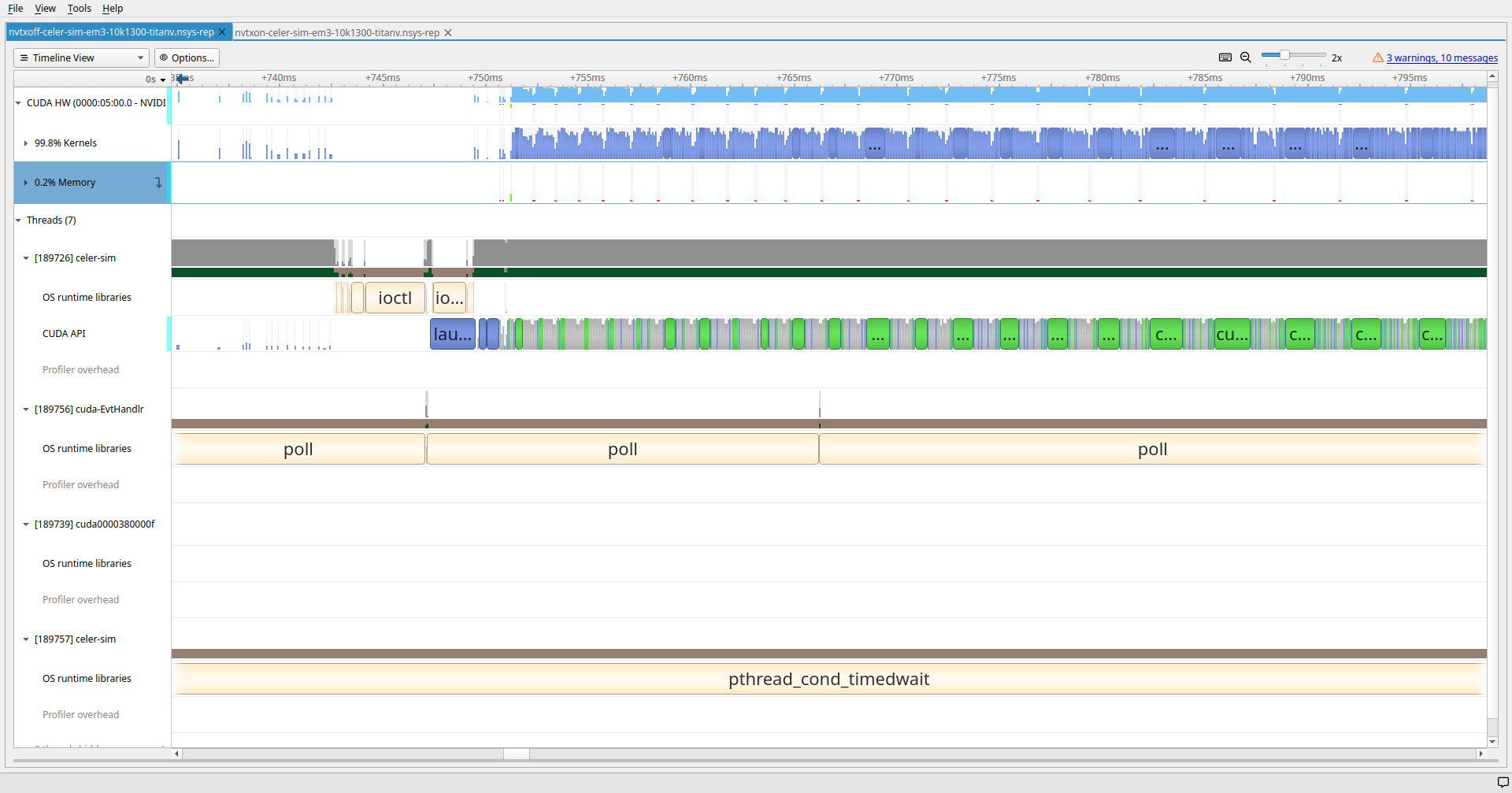
CELER_ENABLE_PROFILECELER_ENABLE_PROFILING

CELER_ENABLE_PROFILE=1 in PR #827Per-step Allocation and Deallocations
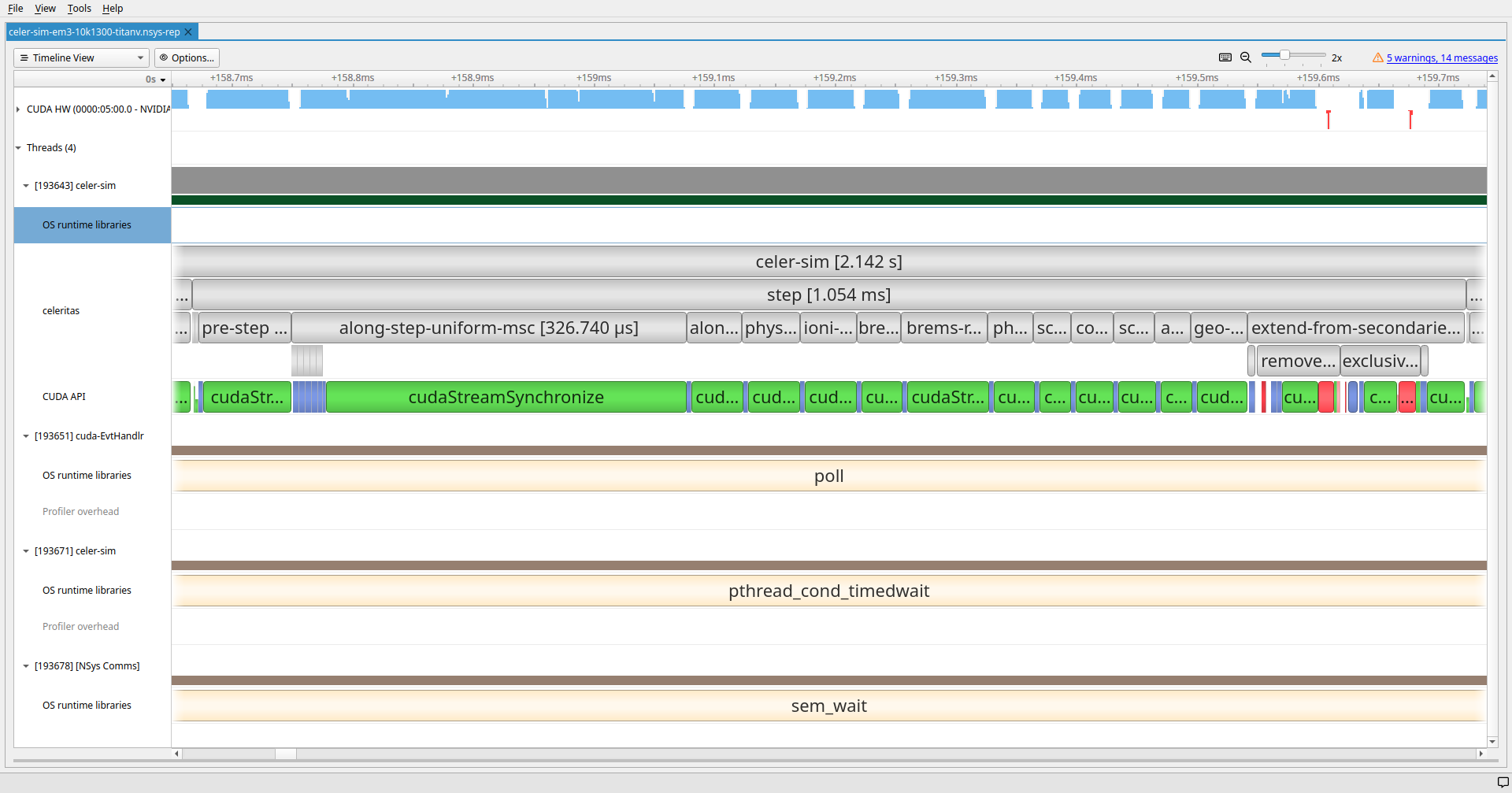
Thrust library callsremove_if_alive
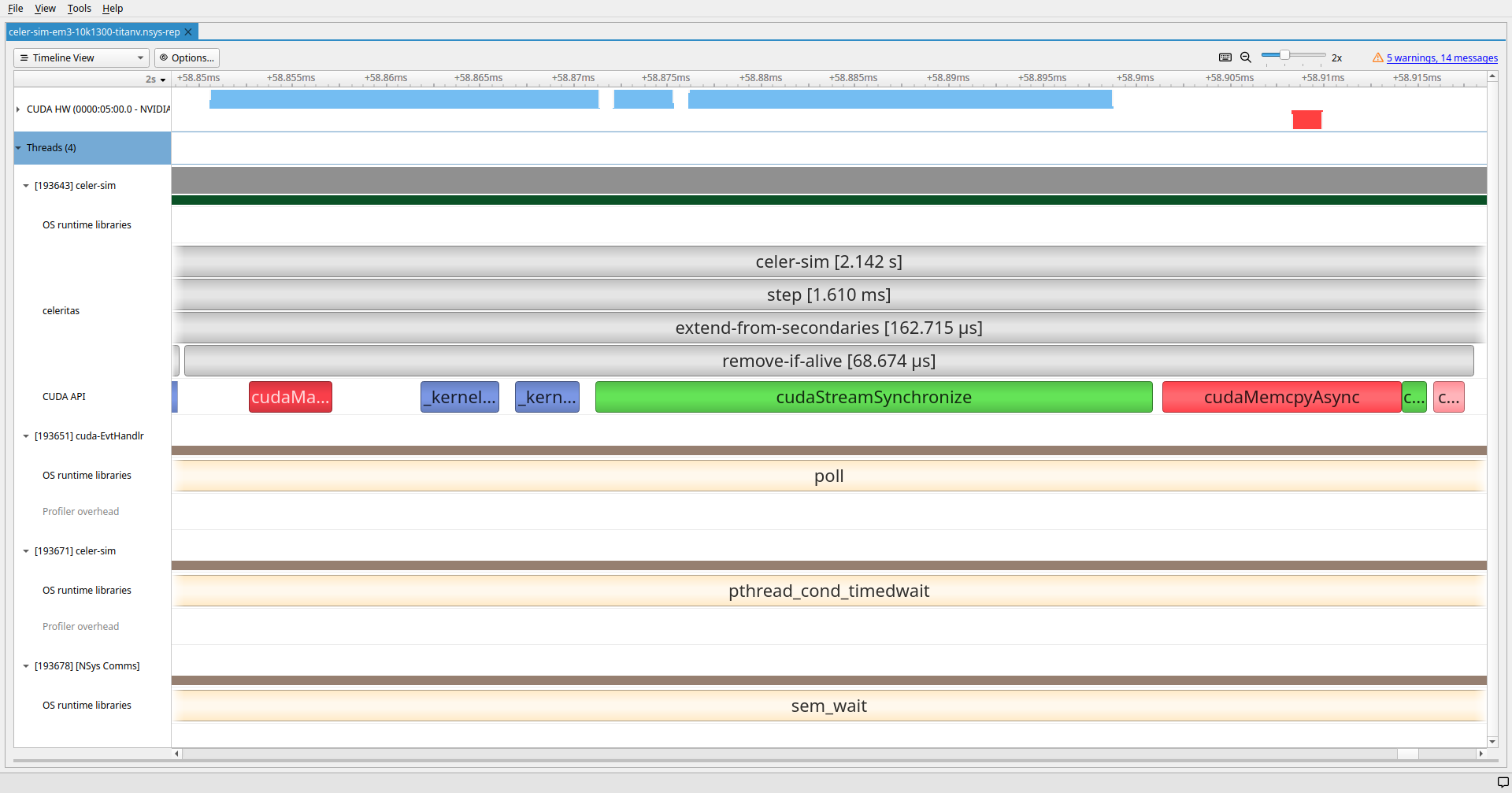
remove_if_aliveexclusive_scan_counts
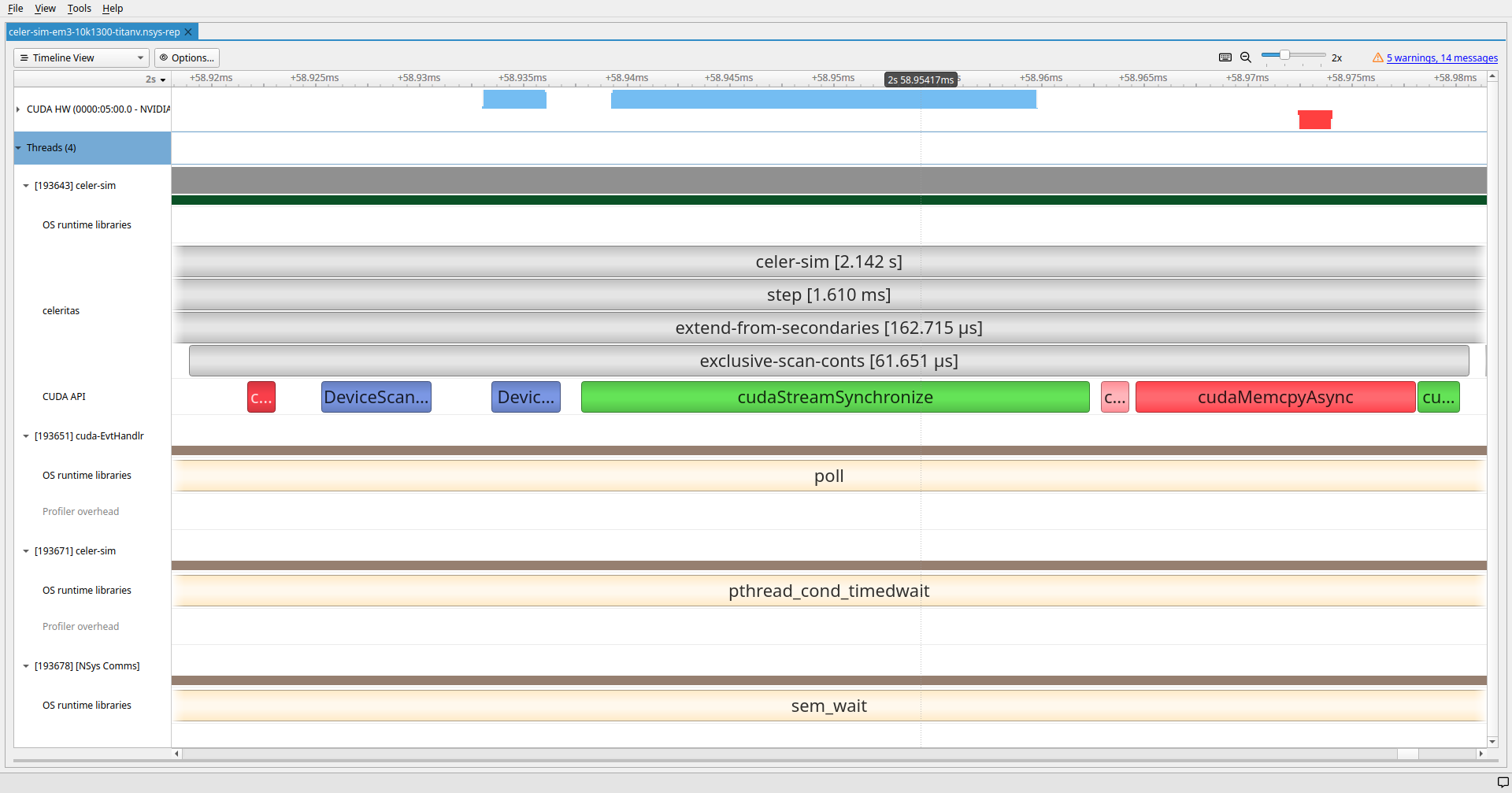
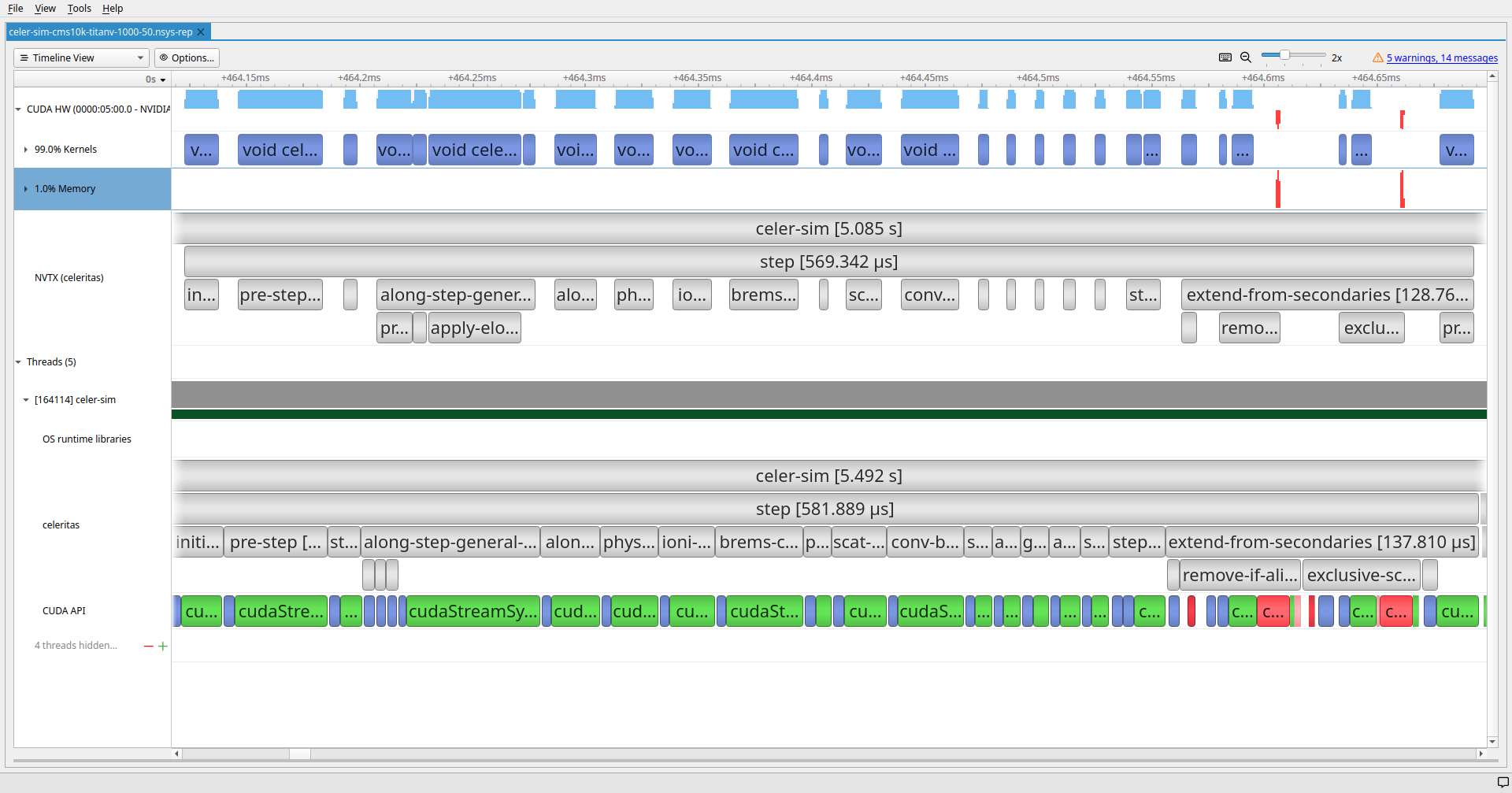
exclusive_scan_countsKernel Launch Overheads
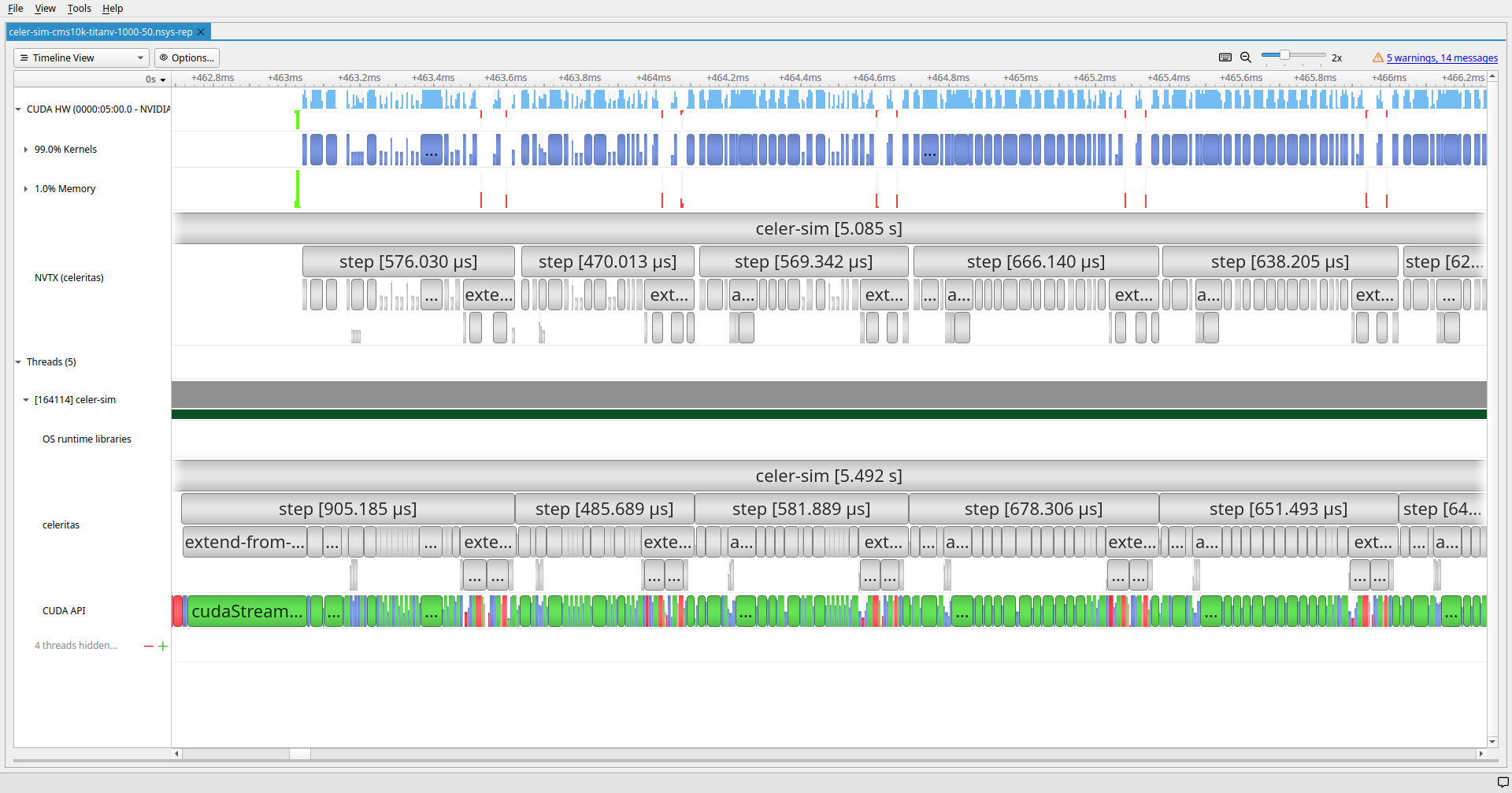
Kernel Launch Overheads
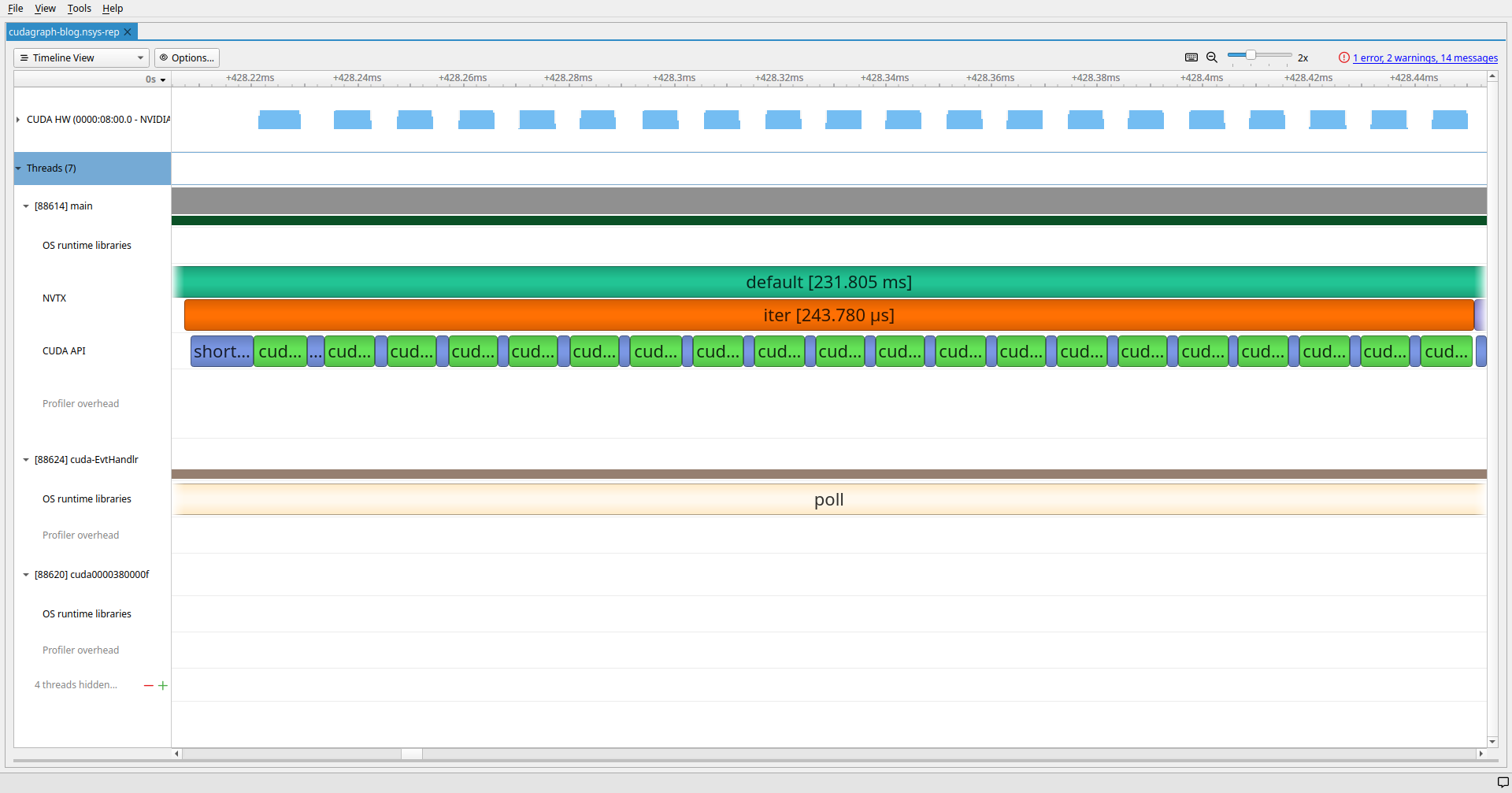
Short Kernels with stream sync
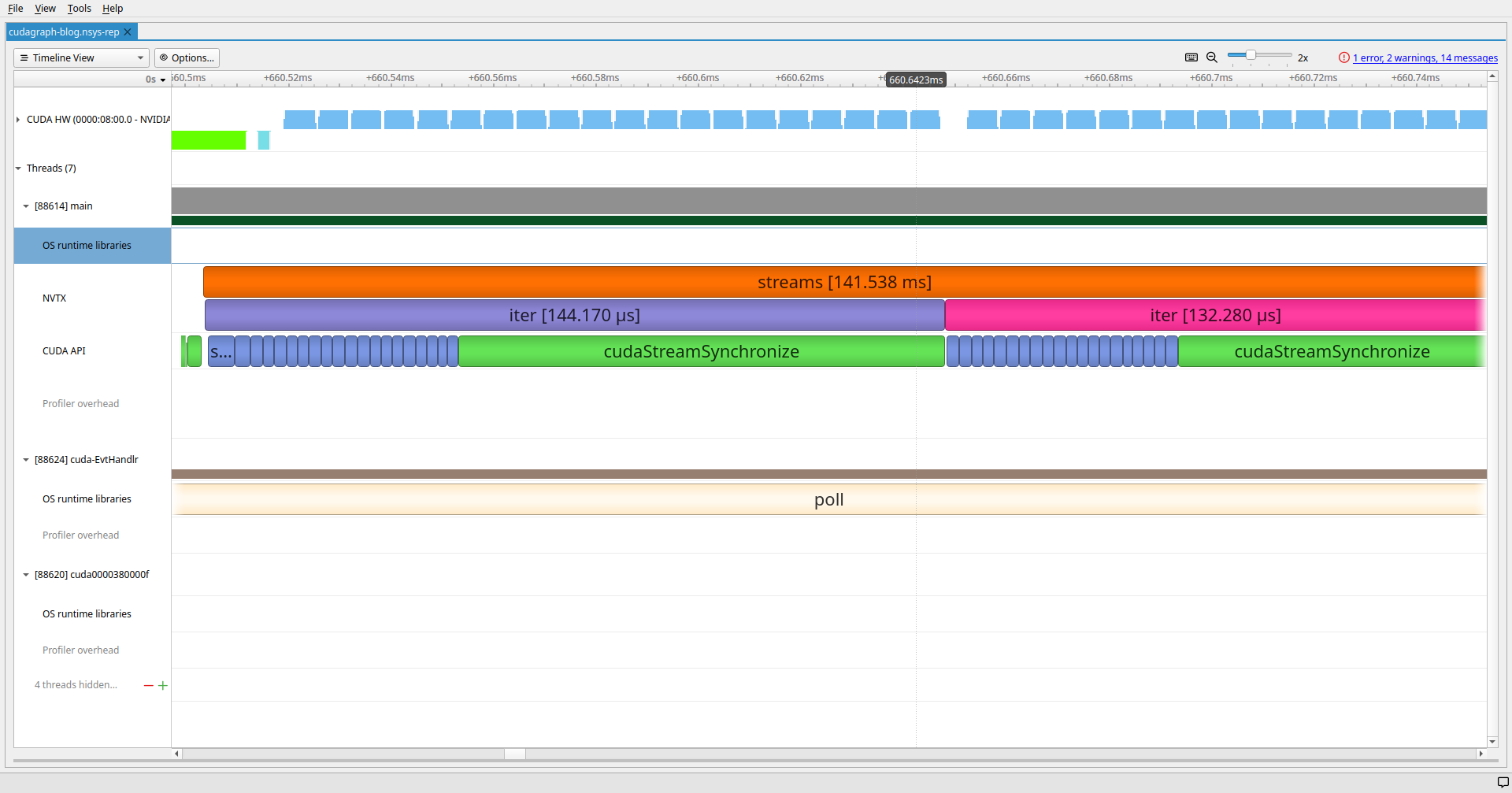
Short Kernels with one sync per iteration
Short Kernels using the CUDA Graph API
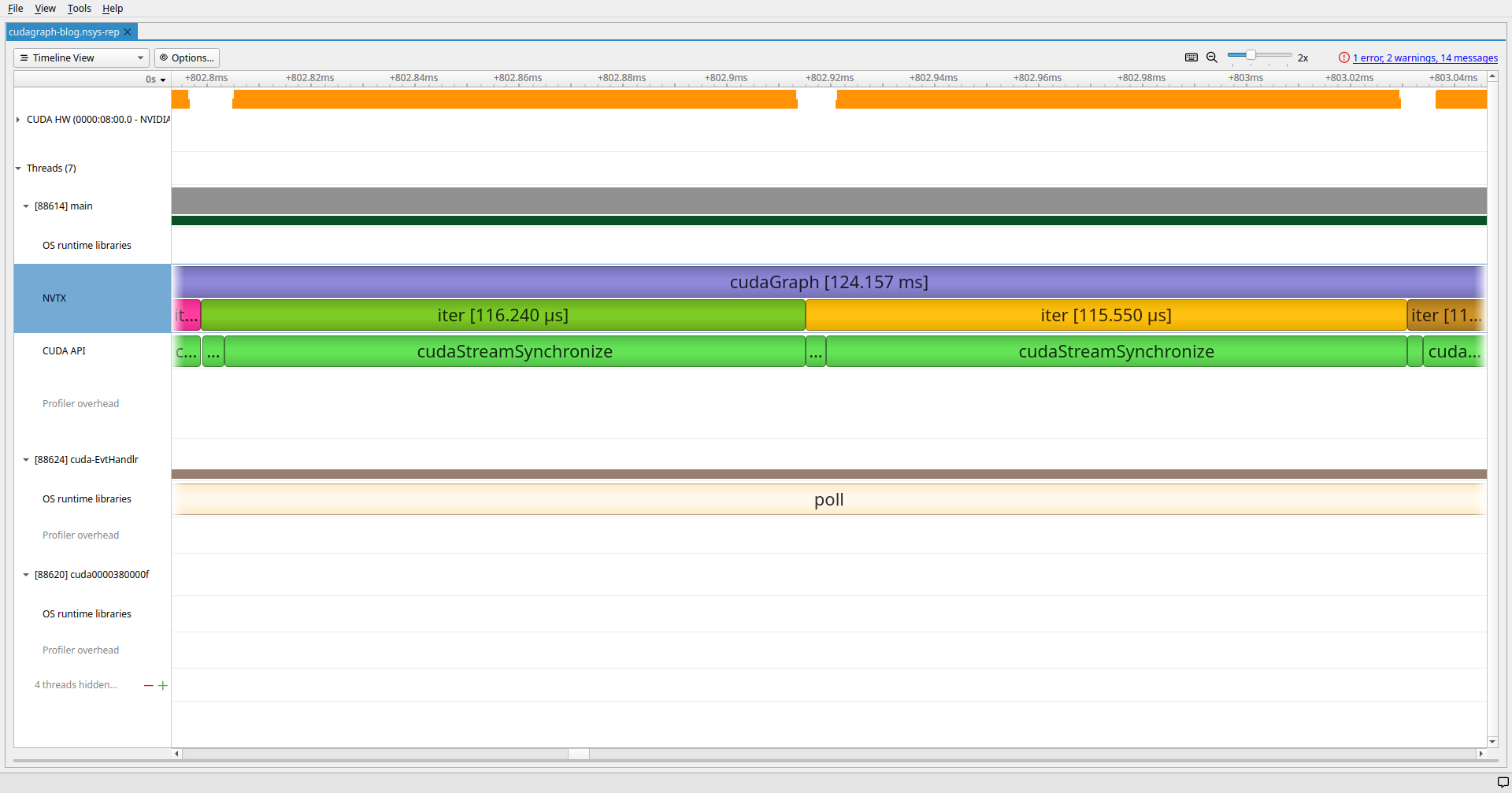
Longest running kernels for TestEM3
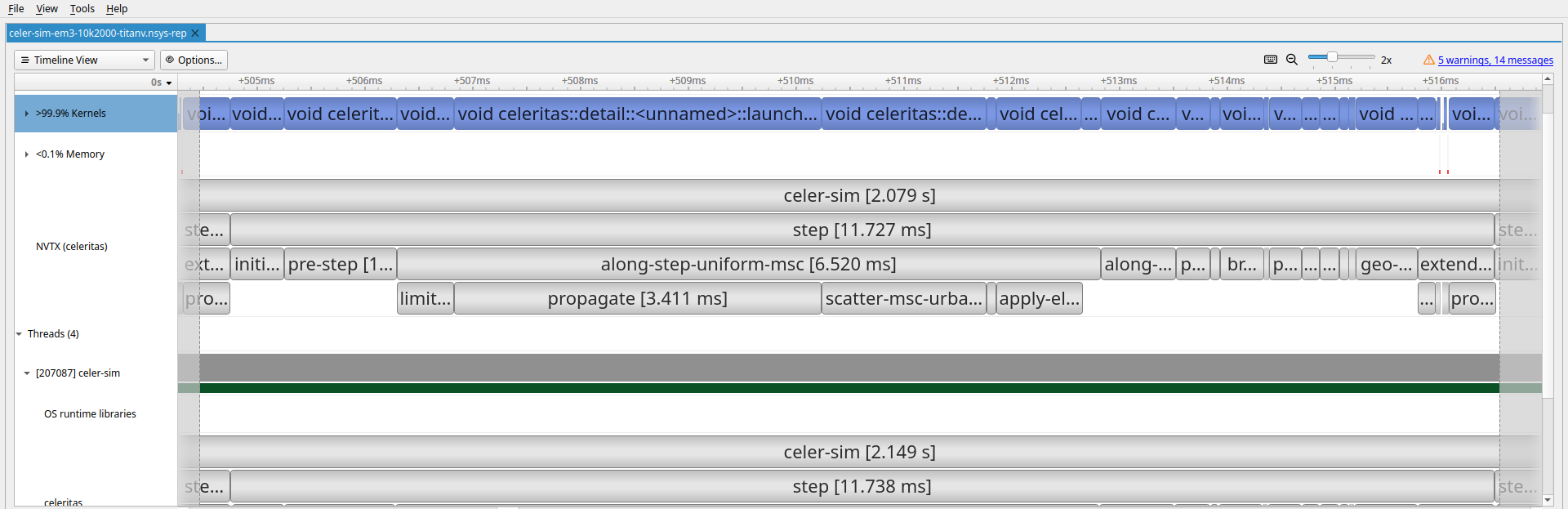
along-step-uniform-msc::propagate IsAlongStepActionEqual with UniformFieldPropagatorFactoryvoid celeritas::detail::<unnamed>::launch_action_impl<
celeritas::ConditionalTrackExecutor<celeritas::detail::IsAlongStepActionEqual,
celeritas::detail::PropagationApplier<celeritas::detail::UniformFieldPropagatorFactory, void>>,
celeritas::detail::PropagationApplier<celeritas::detail::UniformFieldPropagatorFactory, void>,
(bool)>(celeritas::Range<celeritas::OpaqueId<celeritas::Thread_, unsigned int>>, T1)along-step-uniform-msc::propagate
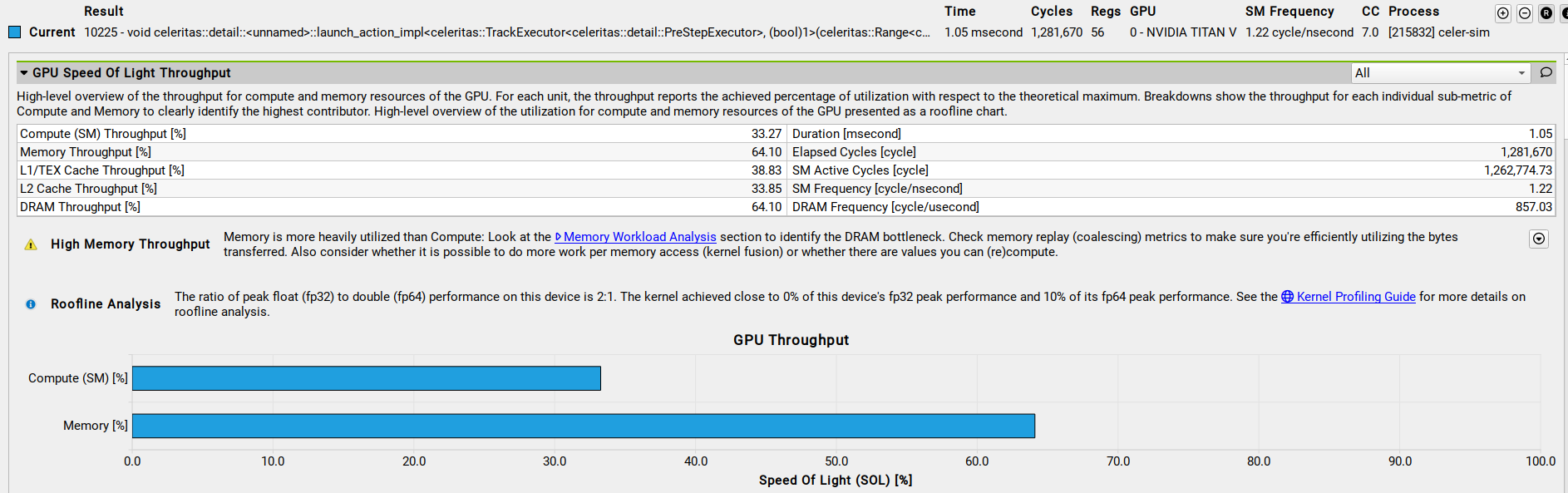
along-step-uniform-msc::propagate kernelalong-step-uniform-msc::propagate

along-step-uniform-msc::propagate kernelalong-step-uniform-msc::propagate
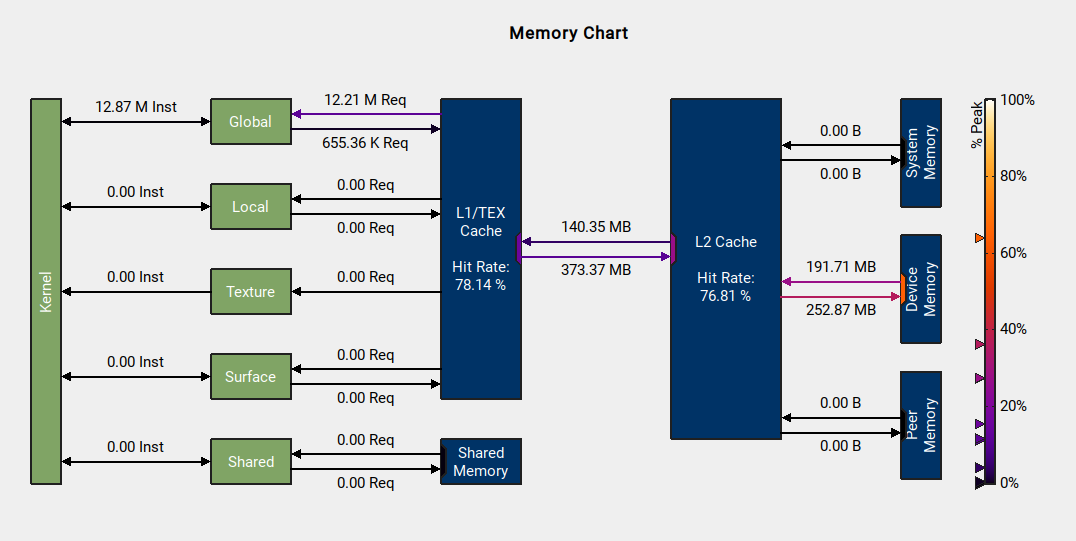
along-step-uniform-msc::propagate kernelGPU memory access pattern
- GPUs perform best when memory accesses are coalesced
- Neighbouring threads reads neighbouring elements of memory
- Reads from global memory are performed 128 Bytes at a time
- So for FP64 data best case is 2 transactions per request
- Worst case 64 transactions

Grace Hopper
- Grace-Hopper GPUs are now being delivered and installed
- Including at least one Tier 2 HPC
- Don’t expect significant benefits compared to SXM H100
- Limited host-device communication

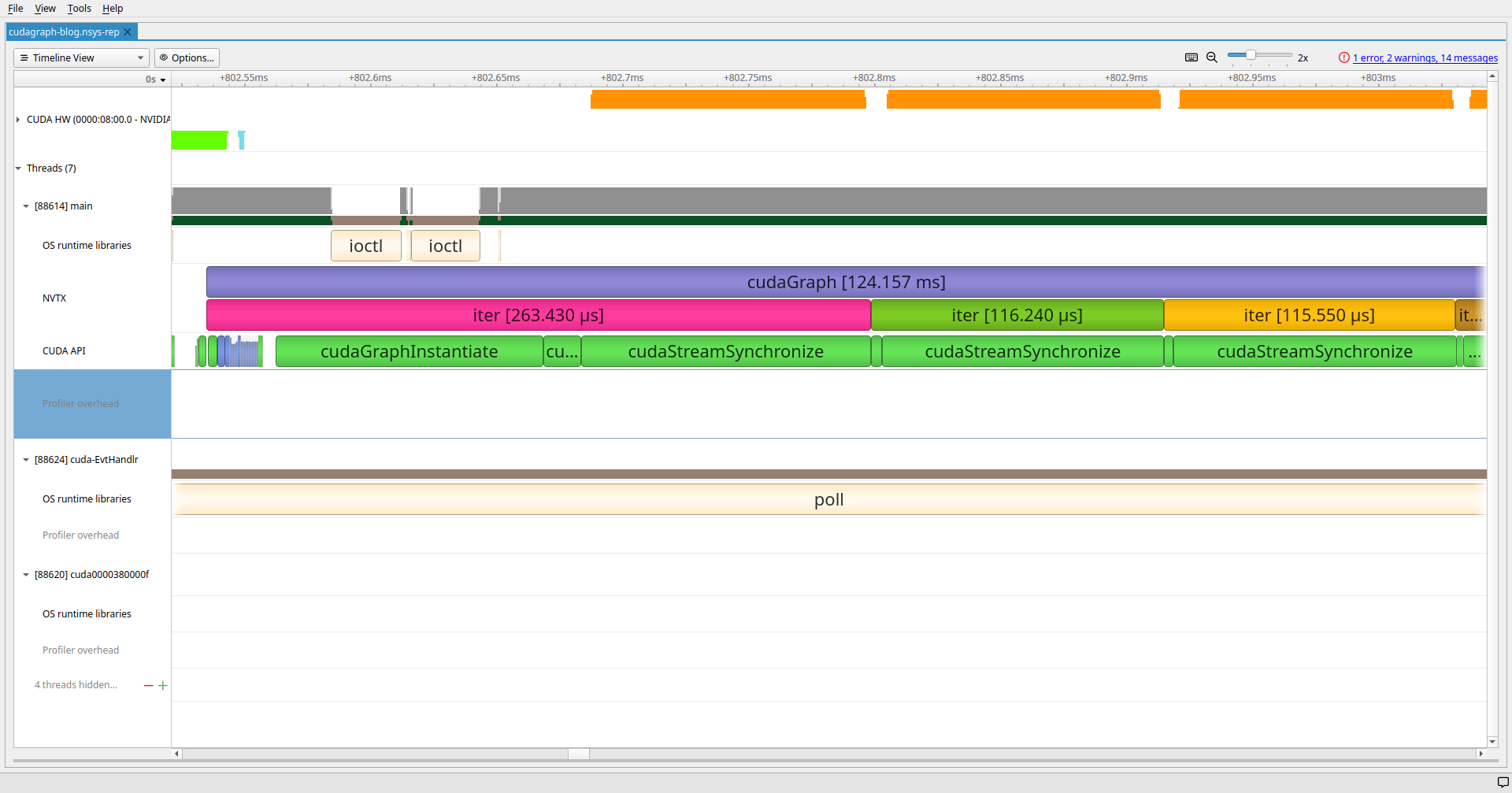
CUDA Graph Capture costs
along-step-uniform-msc::propagate
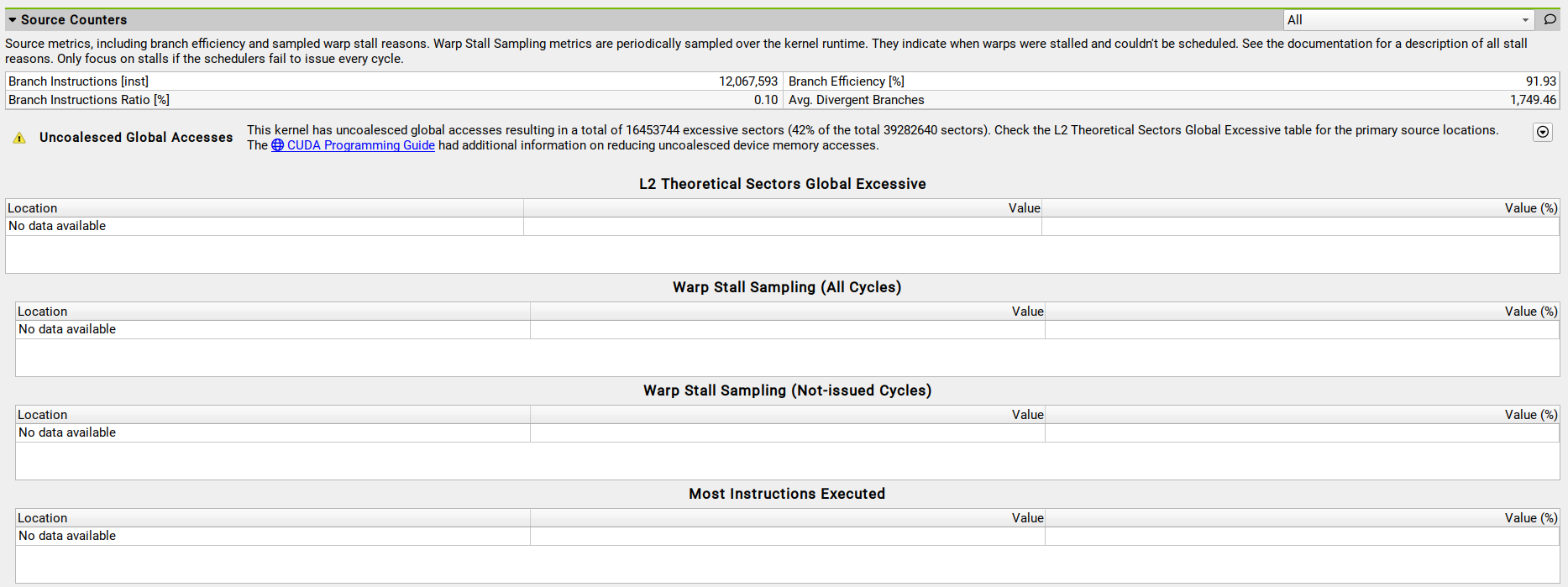
ncu Source counts for a shorter invocation of the same along-step-uniform-msc::propagate kernel. Unfortunately the profile I used for this talk was incomplete / without lineinfo